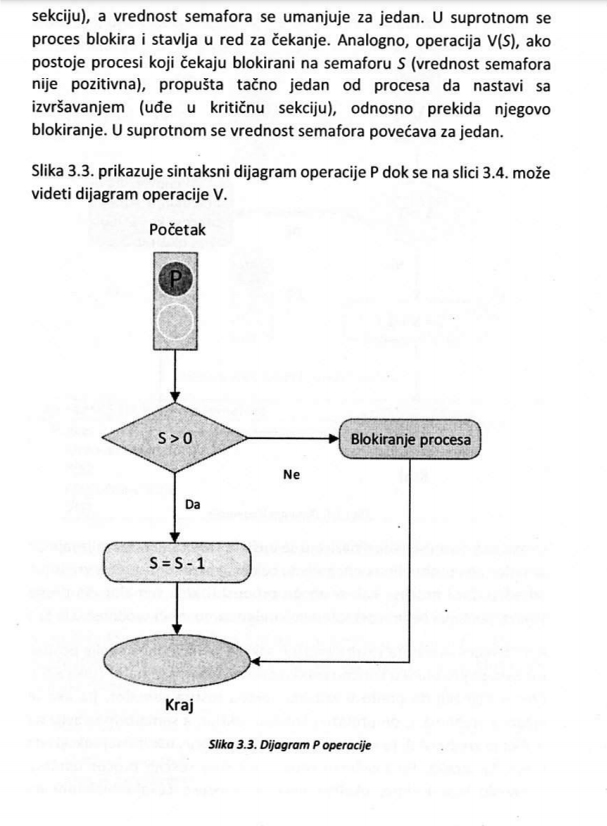
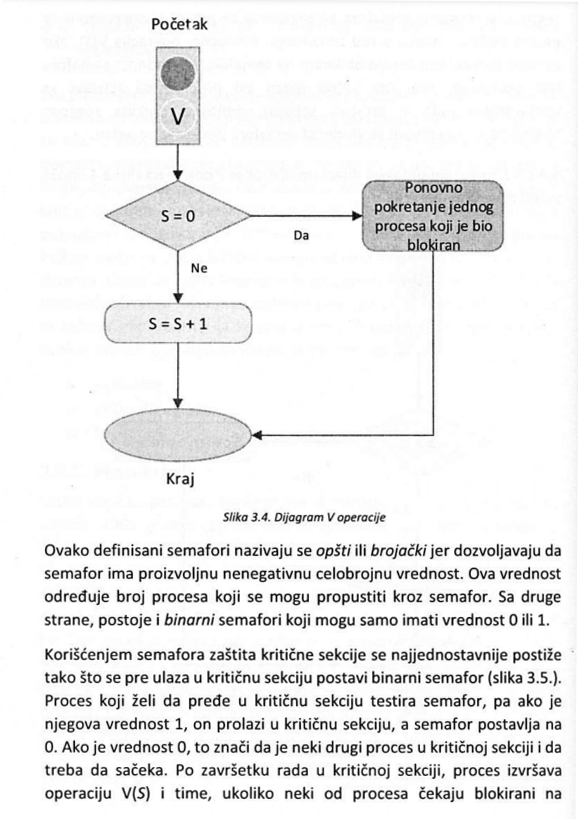
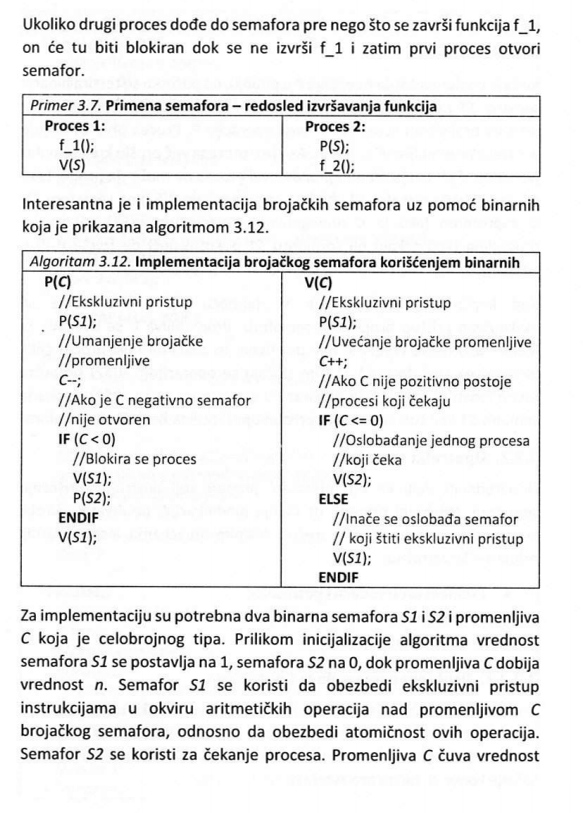
Jedan od ključnih koncepata, kada su operativni sistemi i računarski sistemi u pitanju, predstavljaju procesi.
Proces se definiše kao program u izvršavanju. Kada programer napiše program (izvorni kod) na nekom programskom jeziku, on je u stvari napisao tekst kojim se određeni algoritam implementira na tom jeziku.
Izvorni kod programa predstavlja niz instrukcija koje treba izvršiti i čuva se kao skup znakova (tekst). Prevođenjem napisanog izvornog programa na mašinski jezik, nastaje izvršni program (fajl na nekoj od sekundarnih memorija). Pokretanje izvršnog programa podrazumeva njegovo učitavanje u primarnu (radnu) memoriju računara i izvršavanje na procesoru. Na ovaj način pokrenuti program postaje proces. Proces je aktivan, a operativni sistem je dužan da vodi računa o njemu, tj. da mu obezbedi resurse koji su potrebni za izvršavanje. Da bi obavio zadatak zbog kojeg je pokrenut, procesu su potrebni resursi poput procesora, memorije, ulazno-izlaznih uređaja, fajlova itd.
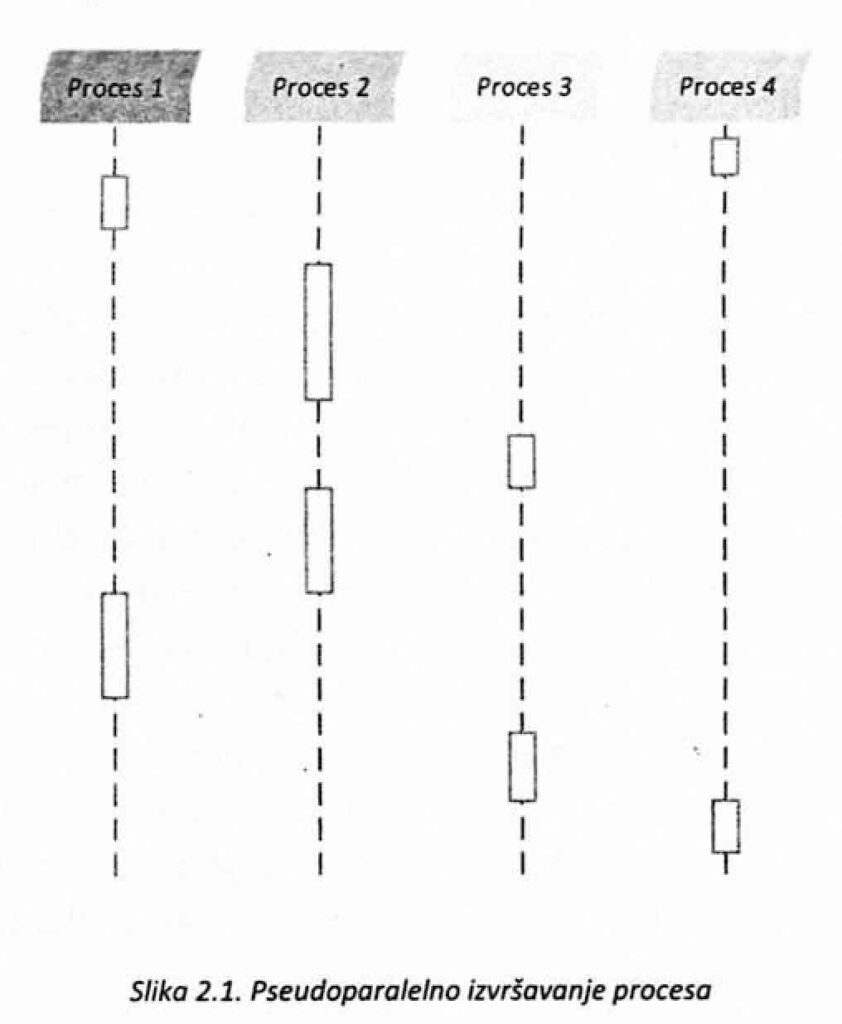
Zadatak operativnih sistema je da obezbede da se procesi mogu efikasno izvršavati. Procesi mogu biti korisnički ili sistemski, a njihovo efikasno izvršavanje najčešće podrazumeva da se izvršavaju konkurentno i (ili) paralelno. Na sistemima čiji procesori imaju samo jedno jezgro, dodeljivanjem procesorskog resursa procesima koji se izvršavaju konkurentno, operativni sistem čini računarski sistem produktivnijim. Na taj način se stvara privid da se procesi izvršavaju u isto vreme, pa se često kaže da se izvršavaju pseudoparalelno. Upravljanje procesima na ovakav način predstavlja osnovni zadatak za operativne sisteme koji podržavaju multiprogramiranje i slične koncepte.
Multiprogramiranje i srodni koncepti podrazumevaju učestalo smenjivanje procesa koji koriste procesor, pri čemu se svaki „po malo” izvršava na procesoru, a prebacivanje se izvršava toliko brzo i često da korisnici imaju utisak da se procesi izvršavaju istovremeno.
Na slici 2.1. ilustrovana je paralelizacija, tj. pseudoparalelno izvršavanje četiri procesa na jednom procesoru. Kao i na slici, vremenski intervali koje procesi dobijaju za izvršavanje ne moraju biti jednaki i određuje ih operativni sistem.
Razvojem procesora i povećavanjem broja jezgara omogućeno je da se i više procesa na različitim jezgrima izvršava paralelno. Principi funkcionisanja su slični kao i u slučaju kada postoji samo jedno jezgro, ali su mogućnosti veće.
Osim izvršnog koda i podataka, bitne informacije o toku izvršavanja procesa sadrže i registri, a posebno programski brojač koji vodi računa o tome dokle se stiglo sa izvršavanjem procesa. Takođe, bitne informacije za svaki proces su i podaci o otvorenim fajlovima, informacije o dozvolama i vlasniku procesa itd.
Zadatak operativnih sistema je da obezbede efikasne mehanizme za: • Kreiranje i brisanje procesa; • Upravljanje procesima; • Komunikaciju između procesa; • Sinhronizaciju procesa.
Proces u memoriji
Za razliku od programa koji je pasivan i opisuje sekvencu instrukcija koje treba izvršiti, proces je aktivan i izvršava se, korak po korak, po algoritmu koji je implementiran u programu. Programski brojač za svaki proces vodi računa o tome dokle se stiglo sa izvršavanjem, tj. koja je sledeća instrukcija. Instrukcije se nalaze u memoriji zajedno sa ostalim podacima koji su potrebni procesu za izvršavanje. Deo memorije namenjen za izvršavanje procesa se može organizovati na različite načine, a najčešći je prikazan u daljem tekstu.
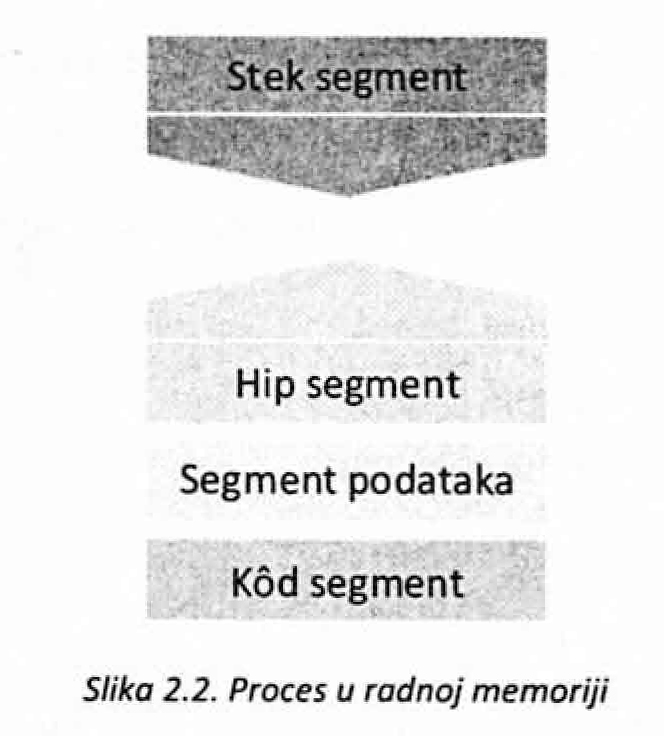
Po pokretanju i učitavanju u memoriju programi, odnosno tada već procesi, obično raspolažu sa četiri dela memorije {slika 2.2.) koji se nazivaju segmenti i to su: • Stek segment; • Hip segment; • Segment podataka; • Kod segment.
Stek segment (Stack segment) sadrži lokalne promenljive i parametre funkcija. Hip segment (Heap segment) je deo memorije u koji se smeštaju podaci koji se generišu u toku izvršavanja procesa, odnosno prostor koji se dinamički alocira u zavisnosti od potreba procesa. Segment podataka (Data segment) sadrži globalne promenljive, a instrukcije koje proces treba da izvrši nalaze se u Kod segmentu (Code segment, Text segment)
Stanja procesa
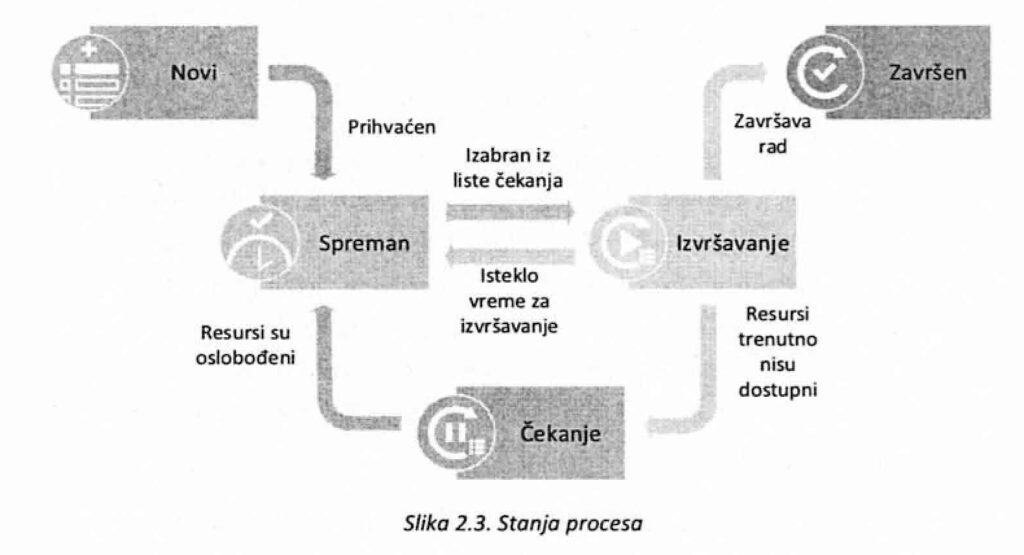
Operativni sistemi definišu skup stanja u kojima se, u zavisnosti od trenutne aktivnosti i situacije u sistemu, procesi mogu naći. Većina sistema podržava sledeća osnovna stanja:
Novi — proces je upravo kreiran, operativni sistem je napravio dokumentaciju koja se odnosi na njega i on pre lazi u spremno stanje
Spreman – proces čeka da operativni sistem donese odluku da mu bude dodeljen procesor
Izvršavanje — proces se izvršava na procesoru
Čekanje — proces se izvršavao ali je za njegov dalji rad potreban neki resurs koji nije slobodan tako da on čeka da se stvore uslovi da bi mogao da nastavi sa radom
Završen — proces je završio sa izvršavanjem i trebalo bi ga izbaciti iz sistema
Na različitim sistemima nazivi stanja mogu varirati. Iz trenutnog stanja proces prelazi u neko drugo u sledećim situacijama (slika 2.3.):
1. Proces prelazi iz stanja Spreman u stanje Izvršavanje kada se procesor oslobodi a operativni sistem, po nekom kriterijumu, izabere njega iz liste spremnih procesa i dodeli mu procesor
2. Proces prelazi iz stanja Izvršavanje u stanje Čekanje u trenutku kada su mu za dalje izvršavanje potrebni resursi koji trenutno nisu dostupni. Na primer, ako želi da odštampa rezultate, a štampač je u tom trenutku zauzet
3. Proces prelazi iz stanja Izvršavanje u stanje Spreman kada istekne vreme koje mu je unapred određeno prilikom dodeljivanja procesora ili ako operativni sistem donese odluku da se proces prekine da bi neki drugi proces došao do procesora. U takvim situacijama proces ponovo prelazi u listu procesa koji konkurišu da dobiju procesor
4. Proces prelazi iz stanja Čekanje u stanje Spreman, kada dođe do potrebnih resursa i spreman je za dalji rad. Pošto se u tom trenutku ne zna da li je procesor slobodan, proces se stavlja u listu spremnih procesa a operativnom sistemu se prepušta odluka kada će mu dozvoliti da ponovo dobije procesor
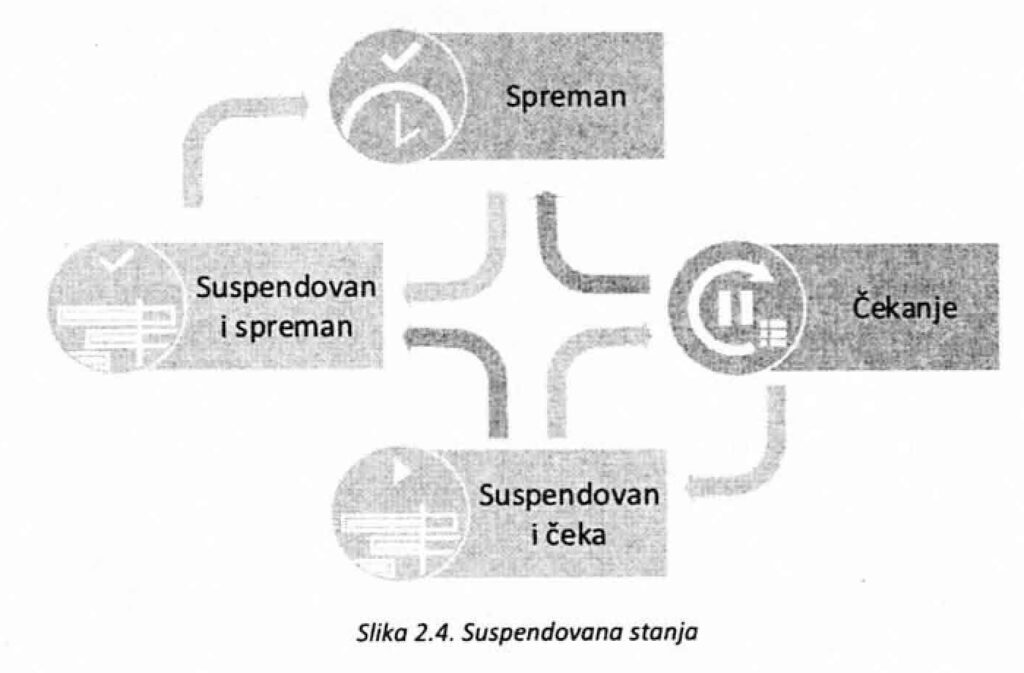
Osim osnovnih stanja, operativni sistemi često podržavaju i suspendovana stanja u koje procesi mogu da pređu na zahtev korisnika ili operativnog sistema.
Procesi koji su u stanju Spreman ili Čekanje se mogu suspendovati i oni onda prelaze u stanja Suspendovan i spreman, odnosno Suspendovan i čeka (slika 2.4.). Suspendovani proces oslobađa resurse koje je zauzimao pre suspenzije i prestaje da konkuriše za druge resurse koji su mu potrebni za izvršavanje, ali i dalje ostaje proces. Često se suspendovani procesi prebacuju na disk do prestanka suspenzije, čime se oslobađa i deo radne memorije koji su zauzimali i na taj način ostavlja više prostora za druge procese.
Do suspendovanja spremnog procesa, odnosno do prelaska procesa iz stanja Spreman u stanje Suspendovan i spreman, najčešće dolazi zbog preopterećenosti sistema zbog velikog broja spremnih procesa, pa je privremeno suspendovanje nekog od procesa poželjno kako bi se operativnom sistemu olakšao rad. Takođe, do suspendovanja može doći i da bi se izbeglo zaglavljivanje sistema ili ukoliko korisnik želi da privremeno zaustavi izvršavanje procesa kako bi dobio mogućnost da proveri međurezultate. Suspendovanje procesa koji je u stanju Čekanje se obično vrši da bi se oslobodili resursi kojima on raspolaže i time sprečilo zaglavijivanje ili ubrzao rad sistema. Kao što je već napomenuto, suspendovanjem procesa se oslobađaju i svi resursi koje je on posedovao čime se drugim procesima omogućava da do njih dođu.
Proces koji je u stanju Suspendovan i čeka prelazi u stanje Suspendovan i spreman, ako se stvore uslovi, tj. oslobode resursi na koje čeka (zbog kojih se našao u stanju Čekanje), tako da po povratku iz suspenzije može da bude u stanju Spreman.
Prekidanje suspenzije procesa koje inicira korisnik ili operativni sistem realizuje se njegovim prelaskom iz stanja Suspendovan i čeka u stanje Čekanje i iz stanja Suspendovan i spreman u stanje Spreman.
Kontrolni blok procesa
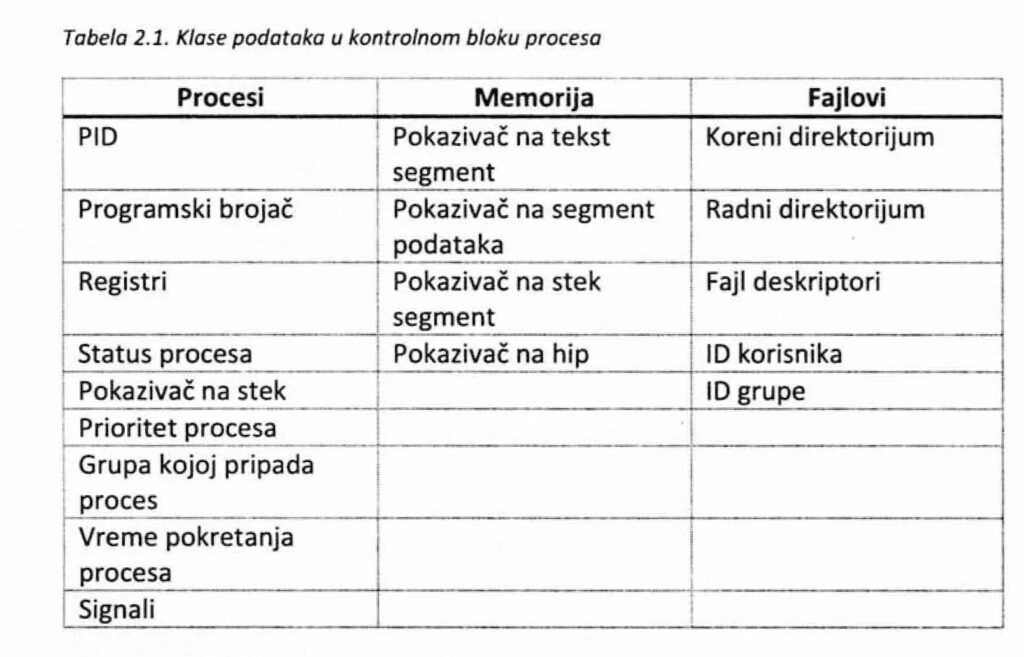
Da bi operativni sistemi bili u mogućnosti da vode preciznu evidenciju o procesima, kao i da bi se olakšala implementacija multiprogramiranja, obično se koriste strukture podataka koje čuvaju informacije o svakom pokrenutom procesu. Ova dinamička struktura se često naziva Kontrolni blok procesa i sadrži najznača jnije podatke koji omogućavaju identifikaciju i upravljanje procesima.
U većini implementacija operativnih sistema kontrolni blok procesa sadrži sledeće informacije o procesima:
1. Jedinstveni identifikator procesa (Process ID — PID) broj koji proces dobija u trenutku pokretanja, tj. svog nastanka. Svi procesi na jednom sistemu imaju različite PID-ove, čime je sistemu omogućeno da ih razlikuje na krajnje jednostavan način.
2. Stanje procesa — informacija o trenutnom stanju u kojem se proces nalazi. Na primer, proces se može naći u nekom od stanja koja su definisana u prethodnom odeljku: Spreman, Izvršavanje, Čekanje, Suspendovan i spreman itd
3. Programski brojač — čuva informaciju o sledećoj instrukciji koju proces treba da izvrši
4. Sadržaj registara procesora – vrednosti koje se nalaze u registrima kako bi proces posle gubitka prava da koristi procesor mogao da nastavi sa radom tamo gde je zaustavljen
5. Prioritet procesa – informacija o važnosti procesa u odnosu na ostale procese u sistemu
5. Adresa memorije gde se nalazi proces — pokazivači na adrese u memoriji gde se nalaze segmenti procesa
6. Adrese zauzetih resursa — kako bi operativni sistem imao informaciju o tome na kojim lokacijama treba da traži potrebne podatke
U tabeli 2.1. mogu se videti neke od klasa podataka o kojima sistem može voditi računa. Generalno, polja koja čine kontrolni blok procesa se mogu razvrstati u one koji se odnose na procese, memoriju i fajlove.
Operativni sistemi obezbeđuju efikasne mehanizme za manipulaciju kontrolnim blokovima procesa kako bi se realizovali sledeći zadaci: • Kreiranje kontrolnog bloka za novi proces; • Uništavanje kontrolnog bloka procesa koji se izvršio; • Promena stanja procesa; • Menjanje prioriteta procesa; • izbor procesa za izvršavanje.
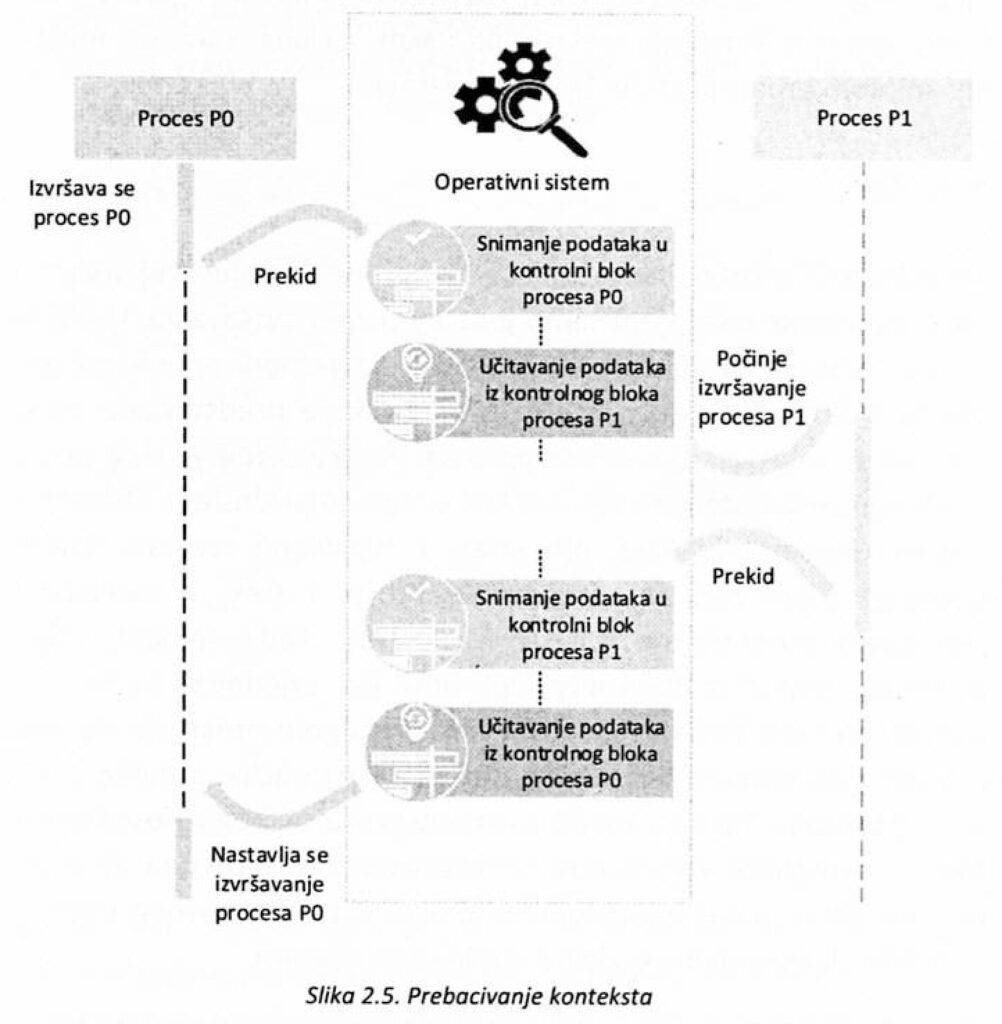
Prebacivanje konteksta predstavlja postupak kojim se proces koji se trenutno izvršava na procesoru prekida, pamte njegovi parametri, a zatim se umesto njega pokreće neki drugi proces i pri tome se učitavaju parametri drugog procesa.
Na slici 2.5. ilustrovan je primer prebacivanja (zamene) konteksta. Proces Po je u stanju izvršavanja, ali bi trebalo da se prekine i da proces P1 krene da se izvršava. Prvo se stanje Po upisuje u odgovarajući kontrolni blok, zatim se učitava kontrolni blok novog procesa i on može da nastavi sa izvršavanjem. Programski brojač procesa P1 dohvata sledeću instrukciju i on počinje da se izvršava. Kada se, iz nekog razloga donese odluka da postoji potreba da se P1 prekine, a proces Po nastavi sa izvršavanjem, upisuju se podaci o izvršavanju P1 u njegov kontrolni blok, a učitavaju se podaci procesa Po.
Modul koji ie odgovoran da izvršava prebacivanje konteksta često se naziva dispečer (Dispatcher). On je zadužen za punjenje registara procesa, prebacivanje u korisnički režim rada i skok na odgovarajuću lokaciju u korisničkom programu kako bi se on nastavio.
Niti
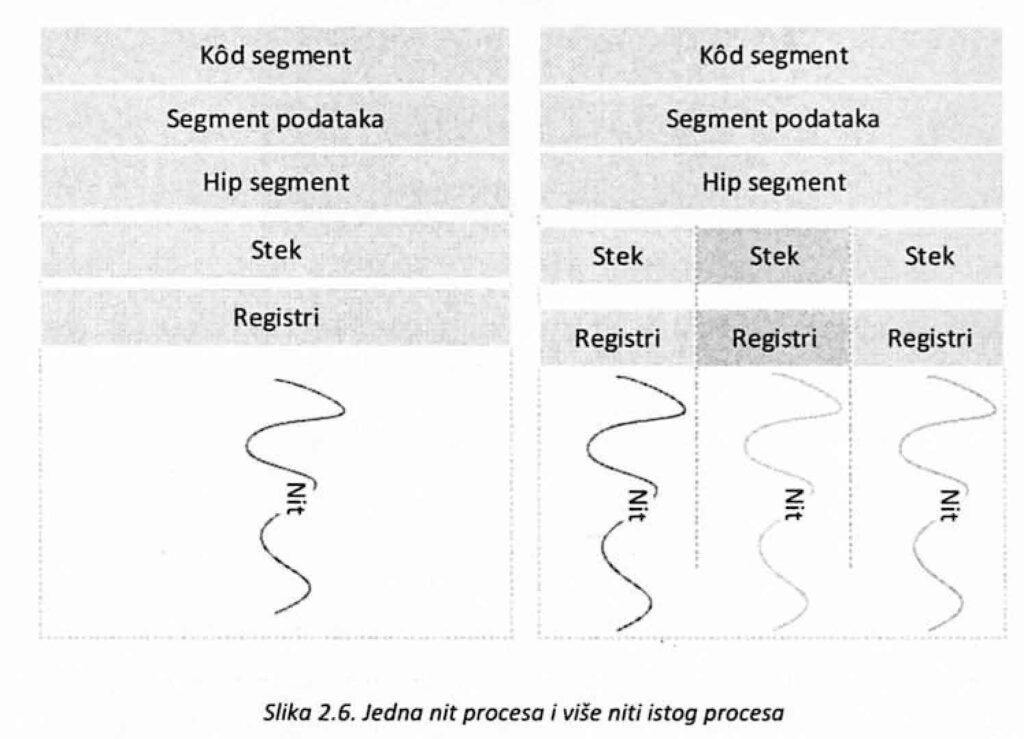
Tradicionalni pristup podrazumeva da procesi imaju svoj memorijski prostor, resurse i da imaju samo jednu jedinicu izvršavanja, tj. da se svi poslovi procesa izvršavaju sekvencijalno. Savremeni operativni sistemi obično podržavaju koncept niti (threads) koje predstavljaju osnovne jedinice za izvršavanje u okviru procesa. Niti su delovi jednog procesa i izvršavaju se korišćenjem resursa koji su njemu pridruženi. Osim resursa procesa kojem pripadaju, niti imaju i sopstvene resurse. Svaka nit poseduje svoje registre, programski brojač i stek, a razlikuje ih i jedinstveni identifikator (thread ID — TID).
Kod segment, segment podataka, podaci o otvorenim fajlovima itd. zajednički su za sve niti jednog procesa (slika 2.6.). Ovakvim pristupom smanjuje se zauzeti prostor i omogućava se da više niti obavlja različite zadatke u okviru jednog procesa. Takođe, korišćenjem niti pruža se mogućnost da se bolje iskoriste prednosti koje donosi višeprocesorska arhitektura. Rad sa više niti (multithreading) podrazumeva mogućnost operativnog sistema da podrži konkurentno ili paralelno izvršavanje više niti.
Na početku izvršavanja svaki proces dobija svoj memorijski prostor i kontrolnu (inicijalnu) nit. Ova nit ima zadatak da obavi potrebne inicijalizacije i kreira ostale niti koje su potrebne za izvršavanje procesa. S obzirom da niti imaju sve karakteristike procesa, pri čemu neke resurse dele sa drugim nitima, često se nazivaju i lakim (lightweight) procesima.
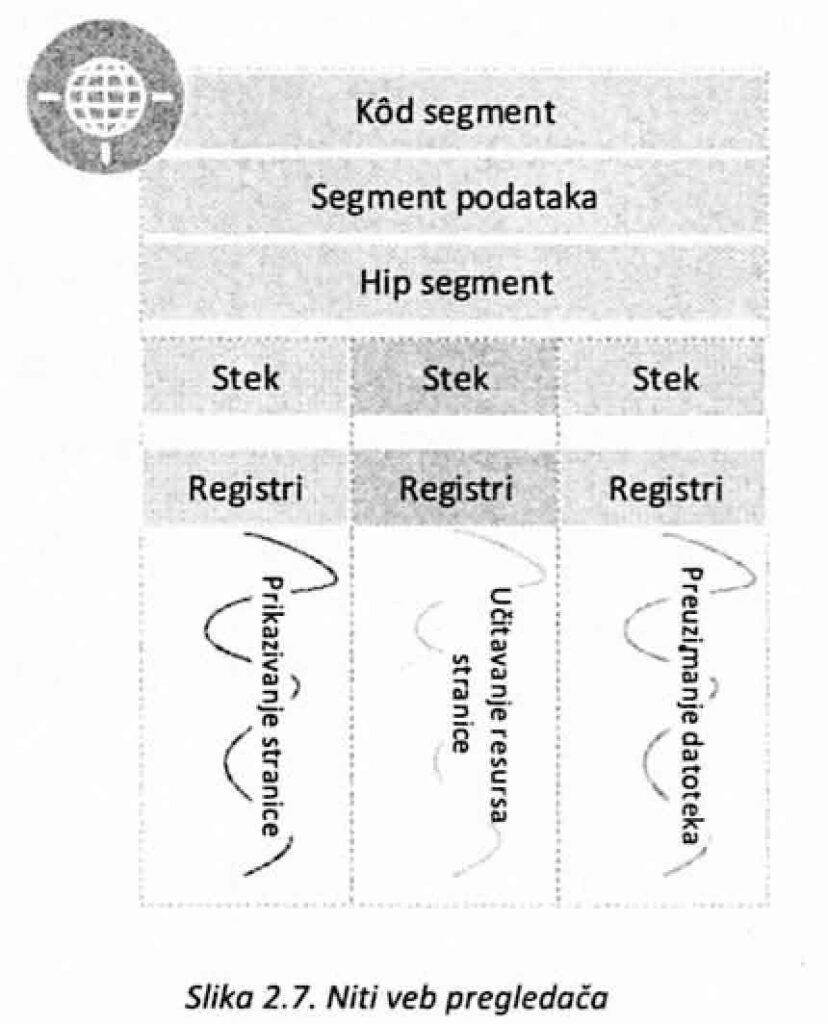
Upotreba niti može se ilustrovati na primeru veb pregledača. Naime, oni se mogu implementirani tako da koriste bar tri niti. Jedna nit služi za prikazivanje hiperteksta u okviru prozora, druga učitava podatke sa nekog servera, dok treća služi za preuzimanje podataka preko mreže (slika 2.7.). Pri tome, ove niti dele podatke kroz zajedničke resurse i istovremeno se mogu izvršavati na različitim jezgrima istog procesora. Slično, tekst procesori mogu imati nit koja prati pisanje teksta, nit koja je zadužena da u određenim vremenskim intervalima sačuva dokument nezavisno od ostalih aktivnosti i nit koja proverava pravopis.
Korišćenje niti donosi mnoge prednosti. Prvenstveno omogućavaju značajne uštede memorijskog prostora i vremena. Niti dele memoriju i neke resurse koji pripadaju istom procesu tako da zauzimaju manje prostora nego kada su u pitanju nezavisni procesi.
Takođe, iz istog razloga, niti se kreiraju mnogo brže od procesa, a i prebacivanje konteksta između niti istog procesa je brže od prebacivanja konteksta između procesa jer se prebacuju samo resursi koji su jedinstveni za nit — stek, registri i programski brojač. Niti pružaju mogućnost aplikacijama da nastave rad u situacijama kada se izvršavaju dugotrajne operacije koje bi, bez podele poslova procesa na niti, privremeno zaustavile izvršavanje ostalih delova procesa. Slično, korišćenjem niti omogućava se rad procesa čiji su delovi potpuno blokirani. Razvojem i ekspanzijom višeprocesorskih sistema do izražaja naročito dolaze prednosti koje donosi korišćenje ovog koncepta jer više niti mogu da se izvršavaju istovremeno.
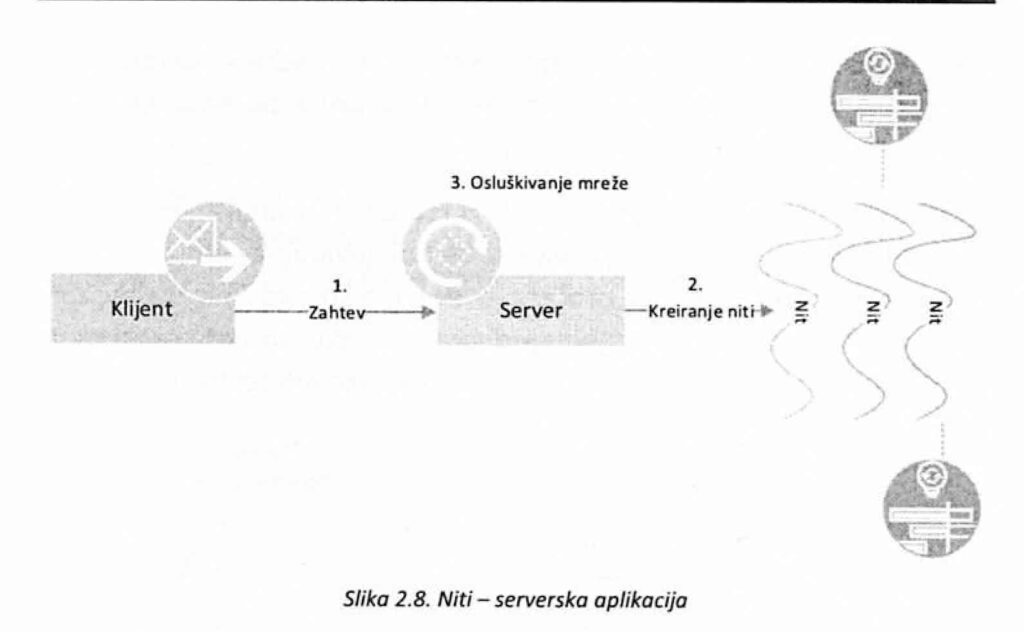
Na primeru serverske aplikacije, koja ima zadatak da opsluži veliki broj klijenata (klijentskih aplikacija) u kratkom vremenskom intervalu, mogu se dobro ilustrovati pogodnosti koje donosi korišćenje niti.
Tradicionalni pristup, bez korišćenja niti, podrazumevao je da serverski proces u petlji čeka da se pojavi klijent, a onda se za svakog novog klijenta kreira novi proces kojem će prepustiti opsluživanje klijenta. Korišćenjem niti, problem se rešava na sličan način, ali se umesto različitih procesa koristi samo jedan u okviru kojeg se može kreirati veliki broj niti. Jedna nit procesa je zadužena da „osluškuje“ mrežu, tj. da prihvata klijente pri čemu se za svakog novog klijenta kreira nova nit (slika 2.8.). Kreiranje niti je brže i zahteva manje prostora nego kada su u pitanju procesi, tako da ovakav pristup omogućava da se mnogo brže odgovori na zahteve, ali i da se opsluži mnogo veći broj klijenata.
U zavisnosti od toga da li se nitima upravlja sa korisničkog ili sistemskog nivoa, niti se nazivaju korisničke ili niti jezgra. Pri tome, pristup procesoru i priliku da se izvršavaju imaju samo niti jezgra, tako da je potrebno napraviti odgovarajuću korespodenciju između korisničkih i niti jezgra.
Ovo se postiže preslikavanjem (mapiranjem) korisničkih u niti jezgra.
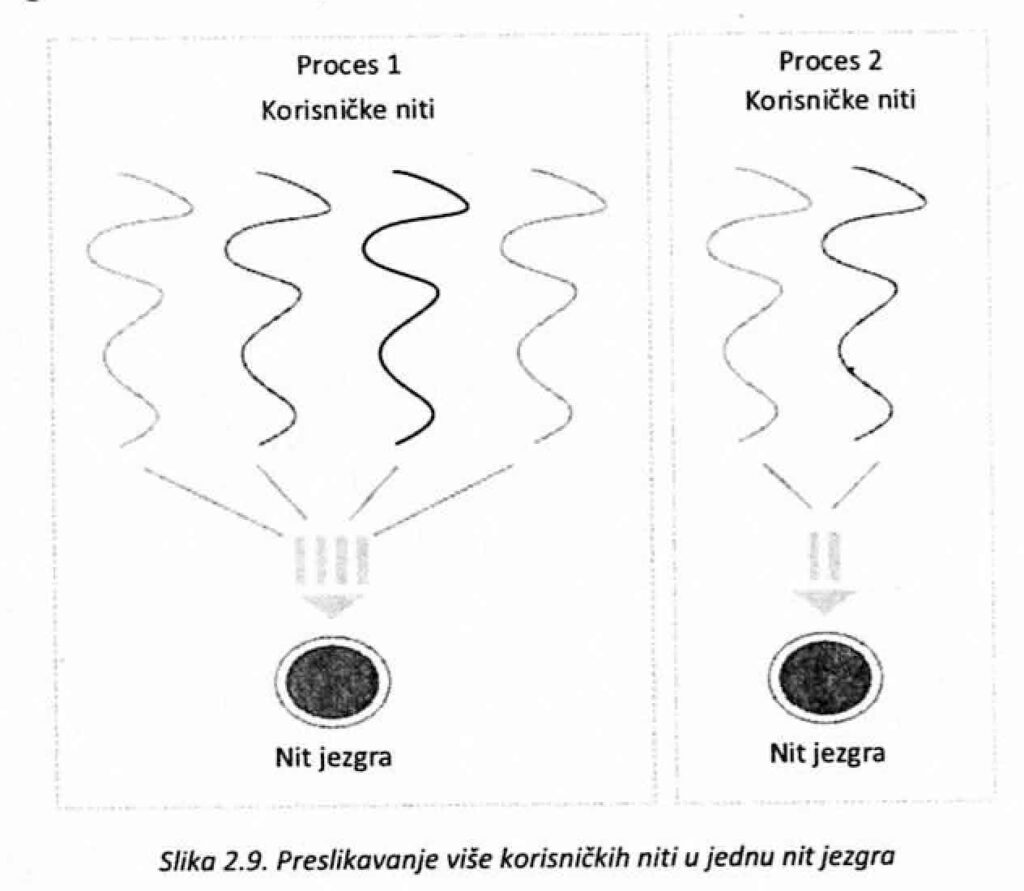
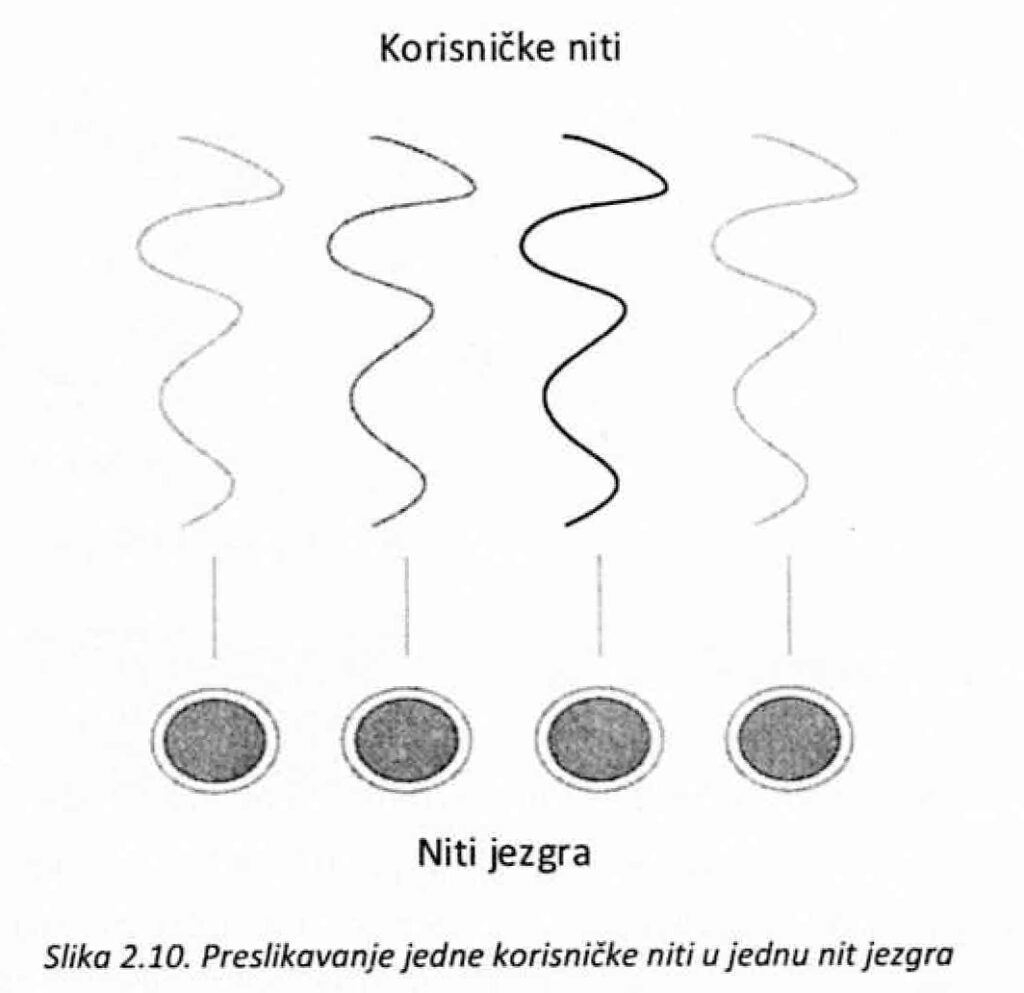
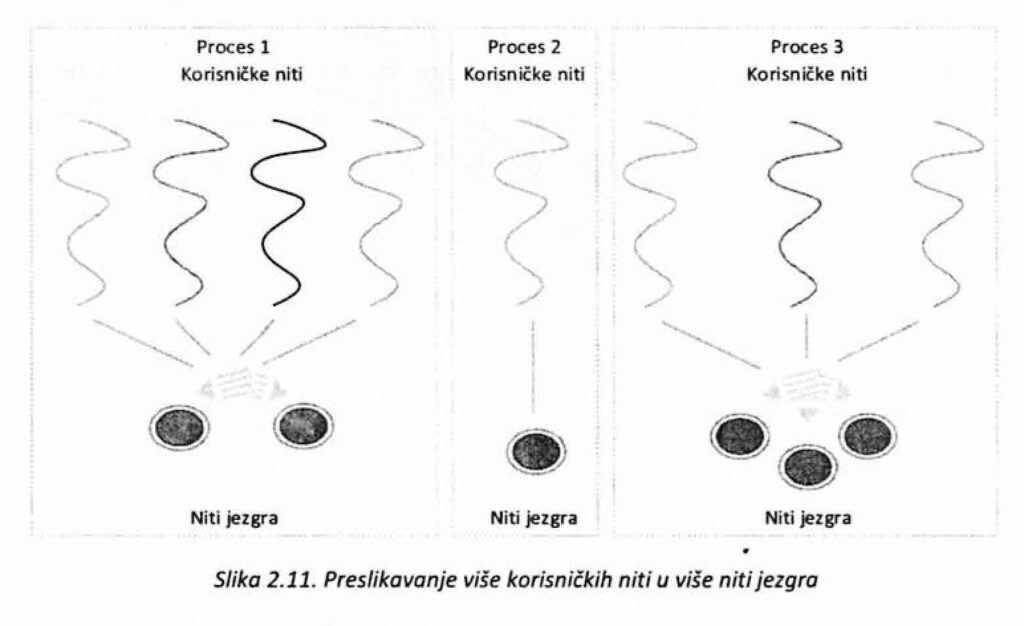
Najčešće podržana preslikavanja su: • Preslikavanje više u jednu; • Preslikavanje jedna u jednu; • Preslikavanje više u više.
Preslikavanje više u jednu (many-to-one) podrazumeva da se više korisničkih niti, sve koje pripadaju jednom procesu, preslikaju u jednu nit jezgra (slika 2.9.). Broj niti jezgra je u ovom slučaju jednak broju procesa koji postoje u sistemu. Dakle, jezgro manipuliše isključivo sa procesima, tako da sve niti jednog procesa izvršavaju kroz jednu nit jezgra. Kod ovakvog pristupa, nitima se upravlja iz korisničkog režima bez uticaja jezgra operativnog sistema. Dakle, odluke o tome koja će se korisnička nit izvršavati donose se na korisničkom nivou. Međutim, jezgro operativnog sistema i dalje upravlja procesima i donosi odluke koja će se od niti jezgra izvršavati na procesoru. Obično se kreiranje, raspoređivanje i upravljanje korisničkim nitima omogućava implementacijom posebnih biblioteka čija je osnovna funkcija da na korisničkom nivou pruže podršku za rad sa nitima.
Glavni nedostatak ovakvog pristupa je u tome što, u situacijama kada se neka od korisničkih niti blokira, blokira se i odgovarajuća nit jezgra, tako da dolazi do blokiranja celog procesa, tj. svih niti koje ga čine. Pošto samo jedna nit može pristupiti jezgru u jednom trenutku, ovakvim pristupom ne mogu da se iskoriste prednosti višeprocesorske arhitekture.
Preslikavanje jedna u jednu (one-to-one) podrazumeva da se svaka korisnička nit preslika u jednu nit jezgra (slika 2.10.). Pri tome, upravljanje nitima potpuno se prepušta jezgru operativnog sistema. Niti jezgra se kreiraju sporije i ima ih manje ali, za razliku o korisničkih niti, jezgro ima bolju podršku za rad sa ovim nitima, a nad njima ima i veći stepen kontrole. Ovakvim pristupom se rešavaju glavni problemi prethodnog modela. Naime, obezbeđuje se konkurentnije izvršavanje niti, jer postoji mogućnost da druge niti istog procesa, nastave aktivnosti u slučaju kada se jedna od njih blokira. Takođe, omogućava se da se više niti jezgra izvršavaju paraleino na sistemima sa više procesora. Najveća mana ovakvog pristupa je ograničavanje broja niti jezgra a samim time i broja niti u korisničkom delu. Naime, zbog toga što se nezanemarljivo malo vremena i prostora troši pri stvaranju i održavanju niti jezgra, mnogi operativni sistemi imaju ograničenje dozvoljenog broja ovakvih niti.
Preslikavanje više u više (many-to-many) je kombinacija (hibrid) prethodna dva pristupa jer podrazumeva da se, u zavisnosti od potreba procesa i mogućnosti sistema, korisničke niti jednog procesa preslikavaju u manji (ili isti u ekstremnom slučaju) broj niti jezgra (slika 2.11.). Broj niti, kao i način raspoređivanja korisničkih na niti jezgra, određuje se na korisničkom nivou, dok se upravljanje prepušta jezgru operativnog sistema. Broj niti jezgra koje će biti kreirane zavisi od konkretnog procesa, ali često i od broja procesora u sistemu. Naime, u sistemima sa više procesora prirodno je da se korisničke niti procesa preslikaju u više niti jezgra. Ovo je najkompleksniji model za implementiranje, ali je i najkvalitetniji jer se može prilagoditi potrebama procesa kao i karakteristikama sistema
Redovi procesa
Jedan od najvažnijih zadataka operativnih sistema je da maksimalno povećaju efikasnost kada je izvršavanje procesa u pitanju. Između ostalog, ovo podrazumeva i da se procesor iskoristi na što bolji način, odnosno da se na njemu stalno izvršava neki od procesa, ali i da se pri tome procesi smenjuju. Prethodno navedeno, u stvari, predstavlja suštinu koncepta multiprogramiranja.
Izvršavanje procesa se obično sastoji od naizmeničnog korišćenja procesora i čekanja na ulazno-izlazne operacije.
Pri tome, da procesor ne bi bio besposlen tokom ulazno-izlaznih operacija procesa koji se izvršava na njemu, nekom drugom procesu se dozvoljava da koristi procesor. Kada procesi obave ulazno-izlazne operacije, onda im je ponovo potreban procesor do sledeće ulazno izlazne operacije i tako do kraja izvršavanja. Na ovaj način se stvara utisak da se procesi izvršavaju paralelno, mada je pseudoparalelno adekvatniji izraz za opisanu situaciju.
Naravno, ovakvo izvršavanje procesa može biti i paralelno u situacijama kada procesor ima više jezgara ili kada u sistemu postoji više procesora.
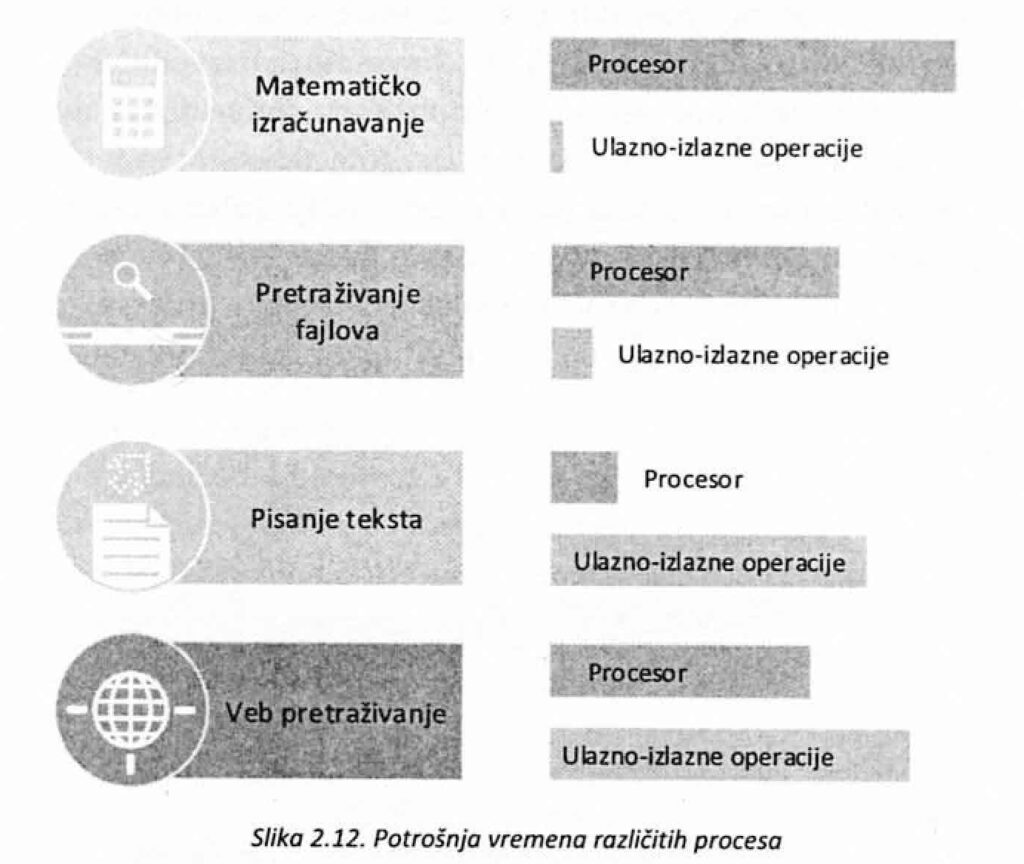
Važno je napomenuti i da neki procesi više vremena troše na ulazno – izlazne operacija, dok drugi najviše vremena u toku svog izvršavanja koriste procesor (slika 2.12.).
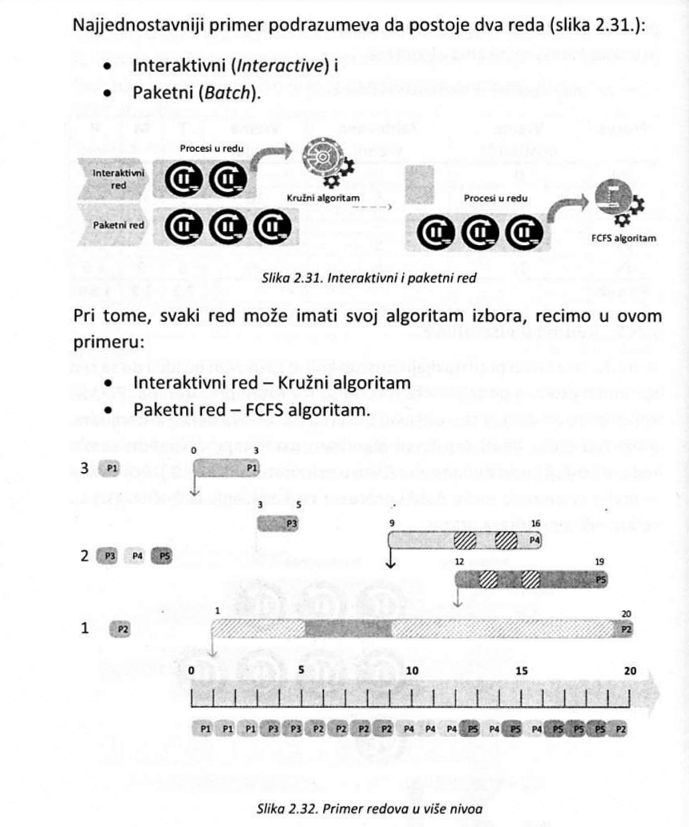
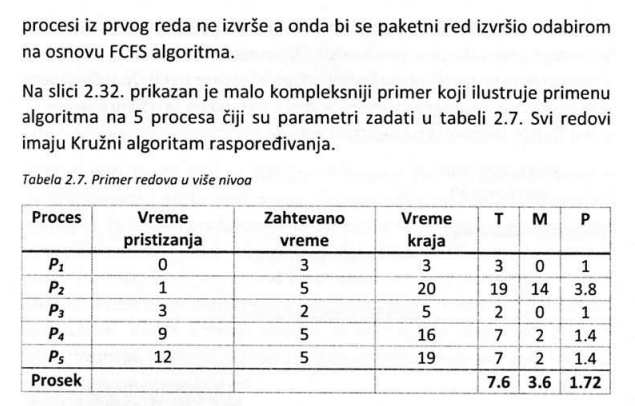
Imajući u vidu činjenicu da postoje različite potrebe procesa kada su procesor i ulazno-izlazni uređaji u pitanju, operativni sistemi obično od svih procesa koji bi trebalo da se izvrše, biraju podskup koji će se odmah učitati u memoriju i izvršavati. Posle početne selekcije, operativni sistem ima zadatak da određuje redosled kojim procesi dobijaju procesor i ostale uređaje i koliko vremena mogu da koriste dobijene resurse. Poslovi ovakvog tipa se obično poveravaju posebnim modulima operativnog sistema koji se nazivaju planeri (schedulers). Da bi se olakšalo upravljanje procesima, uobičajeno je da se formira nekoliko redova procesa. Početni red, u koji se smeštaju pokrenuti procesi, naziva se red poslova. Ovaj red sadrži skup svih procesa u sistemu.
Red spremnih procesa sadrži procese koji su izabrani po nekom kriteriumu koji je određen na nivou operativnog sistema. Procesi u ovom redu su spremni za izvršavanje (nalaze se u stanju Spreman) i smešteni su u glavnu memoriju. Izbor procesa koji će ući u red spremnih trebalo bi da zavisi i od njihovih potreba, odnosno od procene da li će u toku svog izvršavanja više koristiti procesor ili će više vremena provoditi u radu sa ulazno-izlaznim uređajima, jer je poželjno da se napravi dobra selekcija procesa kako bi sistem bio produktivniji.
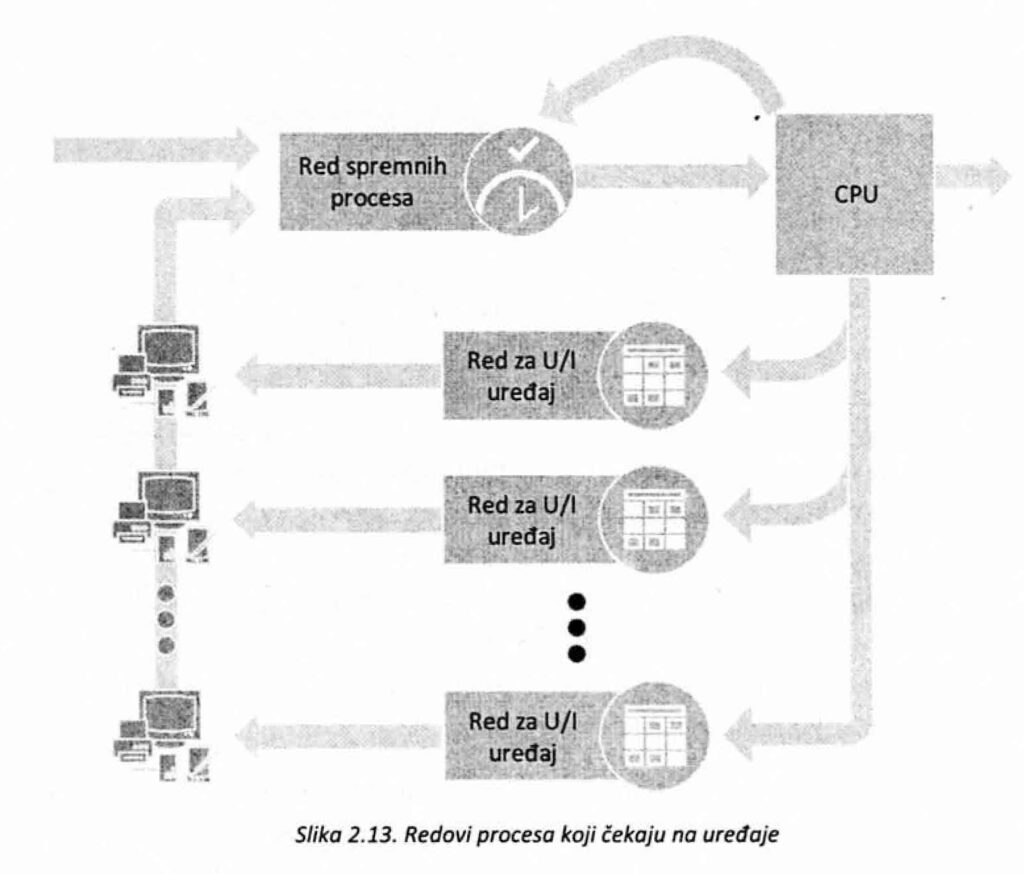
Operativni sistemi vode računa i o redovima procesa koji čekaju na neke od uređaja (slika 2.13). Procesi koji se nalaze u ovim redovima su u stanju Čekanje. Redovi se obično implementiraju kao povezane liste kontrolnih blokova procesa koje ne moraju uvek biti organizovane po FIFO (First In, First Out) principu.
Planeri
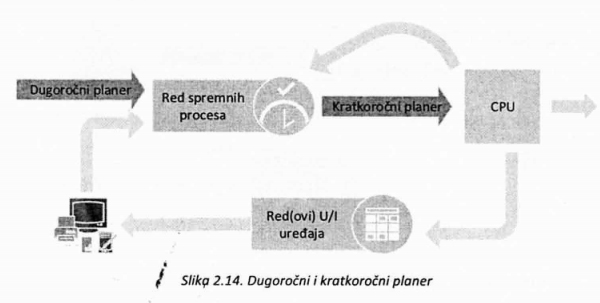
Kao što je već napomenuto, zadatak operativnog sistema je da omogući što veću produktivnost sistema, odnosno da organizuje kretanje procesa kroz različite redove i time omogući njihovo što brže izvršavanje. Odabir procesa i njihovo raspoređivanje po redovima, ali i organizaciju čekanja vrše planeri. Obično postoje bar dve vrste planera: dugoročni i kratkoročni (slika 2.14.). Uz njih se često implementira i srednjoročni planer. Funkcija dugoročnih planera je da od skupa svih procesa koji bi trebalo da se izvrše (iz Reda poslova) izaberu one koji će da se aktivno uključe u sistem i počnu sa izvršavanjem. Drugim rečima, ovi planeri bi trebalo da naprave dobar odabir procesa za red spremnih procesa. S druge strane kratkoročni planeri imaju zadatak da donose odluke o tome koji će se od spremnih procesa izvršavati i koliko dugo će dobiti procesor. Kratkoročni planer se često naziva planer procesora.
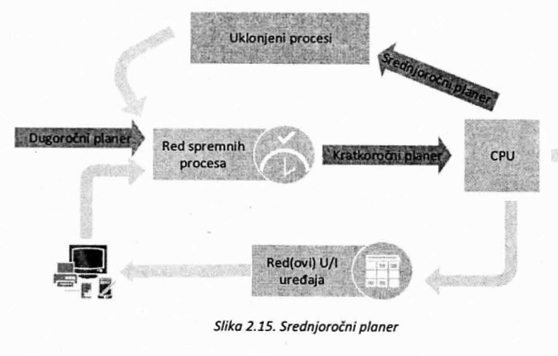
Zbog njihove funkcije u sistemu, kratkoročni planeri se često pozivaju, pa je potrebno da budu implementirani tako da što brže donose odluke. Sa druge strane, dugoročni planeri se ne pozivaju učestalo kao kratkoročni, tako da se može dozvoliti njihov nešto sporiji rad. U praksi, za dugoročne planere je važnije da naprave dobru kombinaciju poslova (strategiju) nego da uštede na vremenu, dok je kod kratkoročnih planera brzina rada važnija od optimalnosti donete odluke. Ponekad se događa da je skup izabranih procesa u memoriji takav da jedni druge ometaju i zaglavljuju, čime umanjuju efikasnost, celokupnog sistema. U takvim situacijama je, često, korisnije ukloniti (suspendovati) neke od procesa iz memorije, nego forsirati viši stepen multiprogramiranja na uštrb efikasnosti. Posle izvesnog vremena, kada se steknu uslovi za to, uklonjeni procesi se mogu ponovo vratiti u memoriju.
Ova šema se naziva prebacivanje (swapping), a izvodi se sa ciljem da bi se poboljšala kombinacija izabranih poslova ili da bi se oslobodila memorija u slučaju zagušenja. Za zadatke ovakvog tipa, obično se na nivou operativnog sistema implementira poseban planer koji se naziva srednjoročni planer (slika 2.15)
Višeprocesorski sistemi
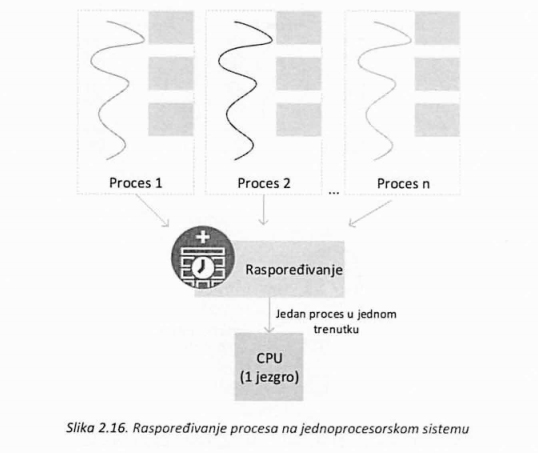
Višeprocesorski sistemi dozvoljavaju veću fleksibilnost kada je rad sa procesima i nitima u pitanju. Naime, planeri operativnih sistema koji podržavaju samo procese i izvršavaju se na jednoprocesorskim sistemima (slika 2.16.), imaju zadatak da vrše odabir procesa koji će se izvršavati i pri tome određuju trajanje njihovih aktivnosti na procesoru.
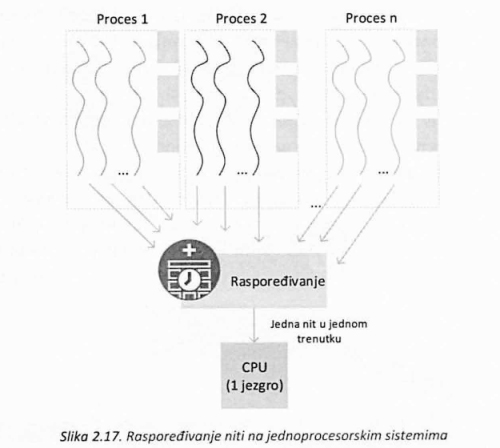
Ukoliko operativni sistemi podržavaju koncept niti i izvršavaju se na računaru sa jednim procesorom onda, slično kao i u prethodnom primeru, niti se mogu smenjivati stvarajući privid da se izvršavaju paralelno (slika 2.17.).
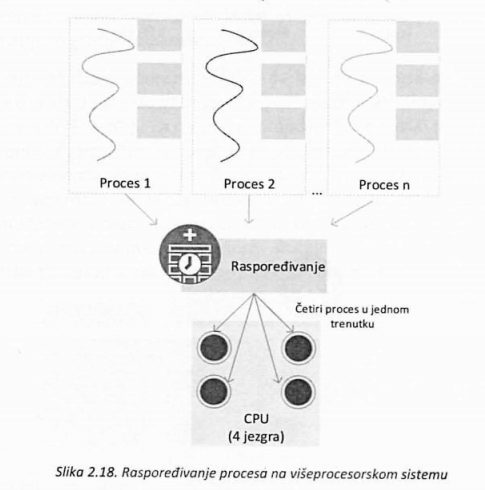
U sistemima sa više procesora, procesi se mogu izvršavati na različitim procesorima (jezgrima) paralelno, što sistem čini efikasnijim u odnosu na prethodno pomenute (slika 2.18).
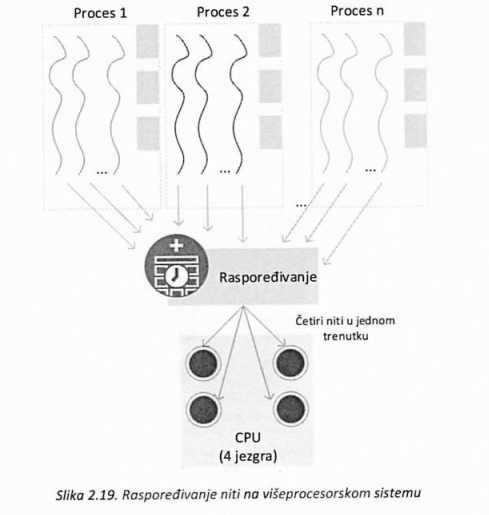
Operativni sistemi koji podržavaju rad sa nitima, a izvršavaju se na višeprocesorskim sistemima su najefikasniji, ali i najosetljviiji jer zahtevaju pažljivo planiranje. Naime, potrebno je obezbediti sinhronizaciju niti istog procesa koje se mogu izvršavati na različitim procesorima. Pri tome, treba voditi računa o tome koliko koja nit (i kada) treba da dobije mogućnost da se izvršava i omogućiti njihovu sinhronizaciju u situacijama kada nekoliko niti istog procesa treba da izvrši zadatke u određenom redosledu.
Procesori savremenih računarskih sistema često imaju više jezgara, a u nekim situacijama i sistemi mogu imati više nezavisnih procesora. U daljem tekstu pod pojmom procesor podrazumevaće se različita jezgra jednog procesora, osim ako se ne naglasi drugačije. Višeprocesorski sistemi omogućavaju veću efikasnost sistema, ali zahtevaju kompleksnije algoritme za raspoređivanje. Kada su u pitanju metode raspoređivanja procesa na različite procesore, postoje dva pristupa: • Simetrično multiprocesiranje; • Asimetrično multiprocesiranje.
Simetrično multiprocesiranje podrazumeva da su procesori ravnopravni i da se procesi raspoređuju na bilo koji od njih u zavisnosti od primenjenog algoritma za raspoređivanje. Kod ovakvog pristupa svi procesori dele zajedničku memoriju, svi imaju pristup ulazno izlaznim uređajima a operativni sistem ih tretira kao ravnopravne.
Asimetrično multiprocesiranje se zasniva na ideji da neki procesori mogu biti zaduženi za određene funkcije. Na primer, jedan procesor se može proglasiti glavnim (nadređenim). Njemu se poverava izvršavanje koda jezgra operativnog sistema a samim time i vođenje računa o ulazno-izlaznim operacijama. Kod takve podele ostali procesori imaju zadatak da izvršavaju isključivo korisničke procese dodeljene od strane glavnog procesora. Sistemi koji podržavaju ovakav pristup su često neefikasni jer se dosta sporih operacija izvršava na jednom (glavnom) procesoru. Iz tog razloga, simetrično multiprocesiranje pokazalo se kao efikasnije u realnoj primeni.
Pri raspoređivanju procesa u višeprocesorskim sistemima mogu se implementirati rešenja koja podrazumevaju jedan zajednički red čekanja procesa za sve procesore ili različite redove čekanja procesa za svaki od procesora. Kod oba pristupa, planeri vode računa o spremnim procesima i biraju sledeći koji će se izvršavati.
Pristup sa zajedničkim redom čekanja omogućava ravnomerno opterećenje procesora. Naime, pošto neki procesor postane slobodan, može mu se dodeliti sledeći proces za obradu. Ovaj pristup se relativno jednostavno implementira, ali pri tome treba voditi računa da se spreči da dva procesora dobiju isti proces za izvršavanje. Takođe, pristup sa zajedničkim redom sa povećanjem broja procesa može dovesti do stvaranja uskog grla.
Kod pristupa sa različitim redovima čekanja za svaki procesor može se dogoditi da procesi čekaju u redovima, a da pri tome postoje slobodni (besposleni) procesori. Ovakve situacije nisu poželjne i treba ih izbegavati a to se obično postiže balansiranjem opterećenja (load balancing).
Balansiranje opterećenja je postupak kojim se teži da se što ravnomernije podele poslovi između procesora. Najčešće se primenjuju dva načina balansiranja = opterećenja: prenošenje migracije (push migration) i preuzimanje migracije (pull migration).
Prenošenje migracije podrazumeva da se iz reda procesa opterećenog procesora neki od procesa pošalju u redove besposlenih ili manje zauzetih procesora (slika 2.20.). Za potrebe prenošenja procesa potrebno je implementirati algoritam za određivanje opterećenja svih procesora, pronalaženje najmanje zauzetog procesora, izbor procesa koji će migrirati itd. Ovaj algoritam se može pozivati nakon što opterećenje nekog procesora pređe određenu granicu ili u određenim (unapred zadatim) vremenskim intervalima. U svakom slučaju treba napomenuti da vremenska složenost ovakvog algoritma nije zanemarljivo mala.
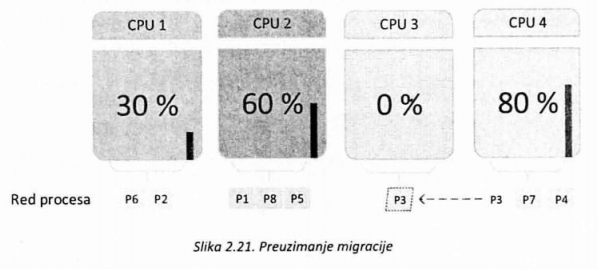
Preuzimanje migracije podrazumeva da se u red slobodnijeg procesora prebace procesi iz redova zauzetijih procesora (slika 2.21.). Za ovakav pristup je potrebno implementirati algoritam za pronalaženje slobodnijih i najzauzetijih procesora, kao i algoritam za odabir koji proces treba preuzeti. Obično se proces za migraciju bira od onih koji su visokog prioriteta ili procesa koji su se malo vremena izvršavali.
Balansiranje opterećenja obično povlači da se proces u celosti ne izvrši na jednom procesoru čime se povećava vremenska složenost izvršavanja.
Naime, prilikom prebacivanja procesa sa jednog na drugi procesor, mora se isprazniti memorija prvog procesora a sadržaj premestiti na drugi što predstavlja izgubljeno vreme. Iz tog razloga procesu se može dodeliti afinitet (sklonost) ka određenom procesoru (processor affinity). Obično se afinitet razvija prema procesoru na kojem je proces počeo da se izvršava. Afinitet procesa prema procesoru može biti slab (soft) ili jak (hard). Slab afinitet podrazumeva da operativni sistem omogućava ali ne garantuje da će proces nastaviti izvršavanje na istom procesoru. Na primer, proces koji je počeo sa izvršavanjem na jednom procesoru može se prebaciti na drugi (u slučaju da je taj pogodniji) i razviti afinitet prema njemu. Jak afinitet podrazumeva da sistem dopušta da se procesu precizno odredi podskup procesora na kojima može da se izvršava. Mnogi sistemi podržavaju obe vrste afiniteta. Afiniteti su u direktnoj suprotnosti sa balansiranjem, tako da pri projektovanju sistema treba voditi računa o tome koji od ova dva pristupa treba da ima prednost.
2.8. Raspoređivanje procesa
Pod raspoređivanjem procesa se podrazumeva donošenje odluka o toku izvršavanja (promeni stanja) procesa koji se nalaze u memoriji. Raspoređivanje bi trebalo da bude što bliže optimalnom, jer od njega zavisi efikasnost sistema. Dobro organizovano raspoređivanje procesa može u značajnoj meri poboljšati brzinu i produktivnost sistema.
Kod jednoprocesorskih sistema u jednom trenutku se tačno jedan proces može izvršavati, dok ostali spremni procesi čekaju da se procesor oslobodi i da budu određeni za izvršavanje. Kada su u pitanju višeprocesorski sistemi, primenjuju se slični mehanizmi za raspoređivanje, samo što sistem na raspolaganju ima više procesora, pa samim tim i više prostora za raspoređivanje. Dodatne mogućnosti pruža i rad sa nitima koje omogućavaju da se delovi procesa izdvoje u posebne celine i izvršavaju pseoudoparalelno na jednom procesoru ili paralelno na višeprocesorskim sistemima.
Algoritmi prikazani u narednom delu će podrazumevati da se operativni sistem izvršava u okviru jednoprocesorskog sistema, a pojam procesa će se odnositi na jedan proces, jedan posao procesa (tosk) ili jednu nit, osim ako se drugačije ne naglasi.
Postoje različiti algoritmi raspoređivanja koji mogu favorizovati određene klase procesa u odnosu na druge, tako da je dobro poznavanje ovih algoritama bitno za odabir prave strategije pri dizajniranju planera operativnih sistema. Kvalitet algoritama se obično ocenjuje na osnovu kriterijuma kao što su:
• lskorišćenost procesora – odnosi se na procenat koliko je procesor bio zaposlen u određenom vremenskom periodu. • Propusna moć – mera koja predstavlja broj procesa koji se mogu završiti u jedinici vremena. • Vreme obrade — vreme koje protekne od momenta pokretanja procesa do njegovog završetka. Konkretno, ovo vreme predstavlja sumu vremena koje proces provede u čekanju da se smesti u memoriju, čekanju u redu spremnih procesa, vremena tokom kojeg se izvršavao na procesoru i vremena tokom kojeg je obavljao ulazno-izlazne operacije. • Vreme čekanja —– ukupno vreme koje proces provede čekajući u redu spremnih procesa. Ovo vreme ne podrazumeva vreme izvršavanja procesa na procesoru kao i vreme koje je proces potrošio na ulazno-izlaznim uređajima. • Vreme odziva – vreme koje protekne od prijavljivanja procesa do trenutka kada se proizvede prvi izlaz programa. Pri tome se ne računa i vreme potrebno da sa taj izlaz prikaže na nekom od izlaznih uređaja. Ovo vreme obično daje veoma realnu sliku o situaciju o sistemu. • Količnik dužine vremena obrade i trajanja izvršavanja procesa. Ovaj parametar može biti veoma koristan jer veoma dobro opisuje situaciju u sistemu.
Imajući u vidu prethodno definisane kriterijume, nameće se zaključak da se pod optimizacijom raspoređivanja procesa u sistemu podrazumeva pronalaženje rešenja koje odlikuje:
– Maksimalna iskorišćenost procesora;
– Maksimalna propusna moć;
– Minimalno vreme obrade;
– Minimalno vreme čekanja;
– Minimalno vreme odziva;
– Konvergencija količnika dužine vremena obrade i vremena izvršavanja procesa ka 1.
Najčešće je nemoguće istovremeno uticati na sve navedene parametre, tako da se, u zavisnosti od željenog rezultata, akcenat može staviti na neke od njih. Obično se za merenje kvaliteta rešenja koriste srednje vrednosti pomenutih parametara. Međutim, u nekim situacijama se akcenat stavlja na ekstremne vrednosti (globalne minim.me i maksimume) nekih od parametara kako bi se rešenje stavilo u željene granice i usmerilo ka cilju.
2.9. Algoritmi planiranja
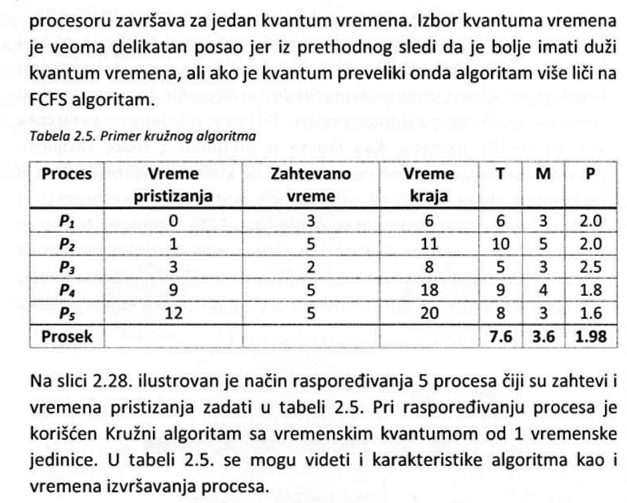
U narednom delu biće prikazani neki od tradicionalnih algoritama planiranja. Pri tome su polazne pretpostavke da sistem sadrži procesor sa jednim jezgrom. Takođe, važno je napomenuti da neki od algoritama imaju i verzije koje dozvoljavaju prekidanje procesa. Prekidanje procesa podrazumeva prebacivanje konteksta procesa koji se izvršava i učitavanje drugog procesa, na osnovu odluke planera, pre nego što je prvi proces iskoristio procesor onoliko koliko mu je bilo potrebno da obavi posao, da dođe do ulazno-izlaznih operacija ili da se izvrši do kraja. Ovakva mogućnost daje veću fleksibilnost pri upravljanju procesima.
2.9.1. FCFS algoritam
Algoritam za raspoređivanje procesa, koji se zbog svoje jednostavnosti i pravednosti obično prvi nameće je FCFS (First Come, First Served). Ovaj algoritam je zasnovan na ideji da se procesor dodeljuje procesima po redu kako su ga zatražili, tj. prijavili se za njegovo korišćenje. FCFS algoritam se jednostavno implementira korišćenjem FIFO [First In, First Out) strukture. Kada se proces pokrene i prijavi za korišćenje procesora, on se tada postavlja na kraj reda. U trenutku kada se procesor oslobodi, tada se prvi sledeći proces izbacuje iz reda i dobija pravo da koristi procesor. FCFS algoritam nema verziju koja bi dozvoljavala prekidanje jer bi to bilo u suprotnosti sa glavnim principom na kojem je zasnovan.
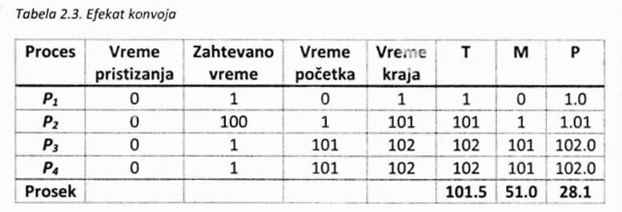
Prednost ovog algoritma je laka implementacija, ali je vreme čekanja često veliko. Takođe, ovakav pristup može dovesti do takozvanog „efekta konvoja“, situacije kod koje dosta procesa čeka da se izvrši jedan vremenski zahtevan proces.
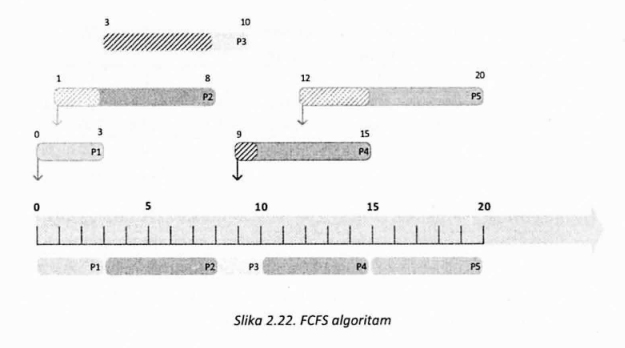
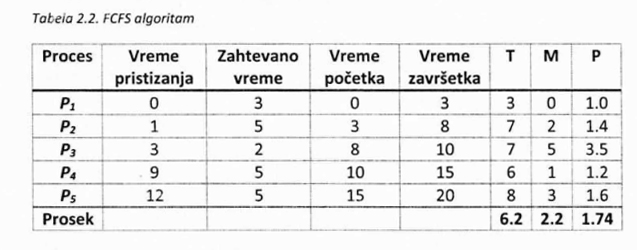
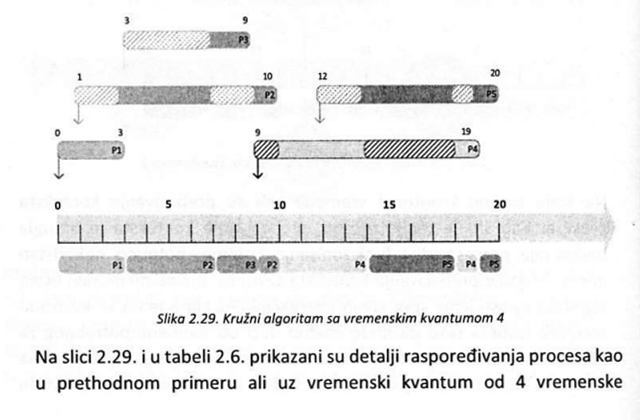
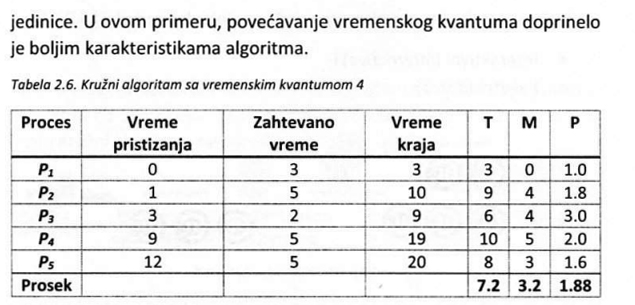
Na slici 2.22. je prikazan primer sistema u kojem se izvršava 5 procesa, dok je u tabeli 2.2. zadato vreme pristizanja procesa u sistem kao i vreme potrebno da se proces izvrši na procesoru.
Tabela 2.2. sadrži i vrednosti početka i završetka izvršavanja procesa ako se primeni FCFS algoritam. Takođe, u tabeli se mogu videti i vremena obrade (T), čekanja (M) i količnik dužine vremena obrade i vremena izvršavanja (P) kada je ovaj primer u pitanju.
U tabeli 2.3. prikazan je primer reda koji sadrži tri mala i jedan veliki proces (P:x)). Kao što ovaj primer pokazuje, procesima koji se dugo izvršavaju FCFS algoritam odgovara za razliku od procesa koji ne zahtevaju puno vremena, a prinuđeni su da čekaju da se pre njih izvrše neki koji se duže izvršavaju.
Ovaj algoritam se obično primenjuje na sistemima ili u situacijama koje ne dozvoljavaju prekidanje procesa već podrazumevaju da se procesima koji su dobili priliku da se izvršavaju na procesoru omogući da završe započeti posao bez obzira na situaciju u sistemu. Paketna (Batch) obrada je dobar primer primene FCFS algoritma u praksi.
2.9.2. SPF algoritam
SPF (Shortest-Process-First) algoritam se zasniva na ideji da se favorizuju procesi čiji je (sledeći) zahtev za procesorom (procesorskim vremenom) manji. Svakom procesu se pridružuje očekivano vreme za njegovo sledeće izvršavanje (posao) na procesoru, a procesor se dodeljuje redom procesima koji zahtevaju manje vremena. Ukoliko se dogodi da dva procesa imaju isto očekivano vreme, obično se primenjuje FCFS algoritam za odluku koji proces će dobiti prednost.
Na slici 2.23. može se videti ilustracija rada SPF algoritma, dok su u tabeli 2.4. prikazani početni parametri za 5 procesa koji se nalaze u sistemu u ovom primeru. U tabeli se mogu videti i vremena bitna za izvršavanja procesa kao i karakteristike predloženog algoritma.
SPF algoritam se može implementirati u verzijama koje dozvoljavaju i koje ne dozvoljavaju prekidanje procesa koji se izvršavaju na procesoru. Razlika između ova dva pristupa je u tretmanu novih procesa koji imaju kraći sledeći zahtev za procesorskim vremenom u odnosu na proces koji se izvršava na procesoru. Naime, ukoliko se dozvoli prekidanje procesa, u situaciji kada se pojavi novi proces čija je sledeća operacija na procesoru vremenski manje zahtevna od one koja se trenutno izvršava, vrši se prebacivanje konteksta procesa koji se izvršava a novom procesu se dozvoljava da na procesoru izvrši operaciju.
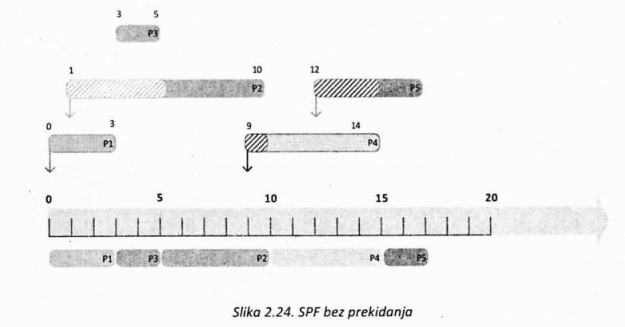
Na slici 2.24. može se videti primer koji ilustruje rad SPF algoritma bez prekidanja. Kada se pojavi proces P5 on će morati da sačeka da proces P4 završi sa izvršavanjem, iako je njegovo vreme potrebno da se izvrši kraće. Naime, u trenutku kada se proces P5 pojavi u sistemu sa potrebom da procesor koristi 2 vremenske jedinice, procesu P4 preostaje još 3 vremenske jedinice da se izvrši do kraja.
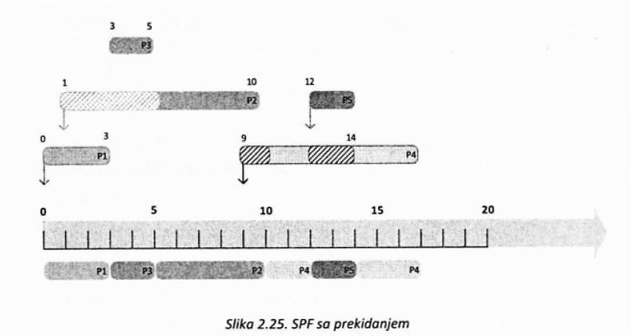
Ukoliko bi implementacija SPF algoritma dozvoljavala prekidanje, u situaciji koja je opisana u prethodnom primeru, proces P5 bi prekinuo proces P4 i preuzeo procesor, jer mu je manje vremenskih jedinica potrebno da se izvrši. Slika 2.25. ilustruje ovaj slučaj.
SPF algoritam je optimalan kada se posmatra srednje vreme čekanja za bilo koji skup poslova. Ovo tvrđenje je trivijalno dokazati, jer je očigledno da premeštanje kraćeg posla pre dužeg smanjuje vreme čekanja kraćeg posla više nego što povećava vreme čekanja dužeg.
Najveći problem, kada je ovaj algoritam u pitanju, predstavlja određivanje dužine sledećeg zahteva za procesorom, odnosno procena dužine trajanja sledeće aktivnosti procesa na procesoru (do ulazno izlazne operacije ili završetka procesa). Kod dugoročnog planiranja, kao procena se može uzeti unapred zadata granica vremena potrebnog da se posao završi. U takvoj situaciji efikasnost sistema zavisi od mogućnosti da se realno proceni trajanje posla, jer manja vrednost očekivanog vremena potrebnog za njegovo izvršavanje povlači da se takvi poslovi favorizuju i da brže dođu na red za izvršavanje. Ovaj algoritam se teže primenjuje na kratkoročno planiranje jer nema pouzdanog načina da se precizno odredi trajanje sledeće aktivnosti procesa na procesoru.
Pristup koji daje dosta dobre rezultate zasniva se na aproksimaciji vremena. Obično se za predviđanje dužine sledeće aktivnosti koristi eksponencijalna sredina prethodnih aktivnosti i prethodnih procena potrebnog vremena. Obično se za predviđanje dužine sledeće aktivnosti koristi eksponencijalna sredina prethodnih aktivnosti i prethodnih procena potrebnog vremena. Drugim rečima, koristi se pretpostavka da će sledeća aktivnost biti slične dužine kao prethodne i procenjene za taj proces. Dužina trajanja sledeće aktivnosti procesa Tn+1 se može aproksimovati sledećim izrazom: